MongoDB Monitoring
MongoDB monitoring is fast and easy to setup with OpsDash. You can quickly start monitoring your MongoDB instances using the zero-dependency single-binary OpsDash agent. OpsDash provides a well-thought-out dashboard that displays metrics that are most relevant to the health and performance of the MongoDB instances being monitored. This means that you can start monitoring your MongoDB instance right away, since it takes just a couple minutes to setup OpsDash monitoring, No messing around with individual metrics, figuring out which of them are important, no editing graph templates.
Here’s how OpsDash’s curated dashboards come out of the box:
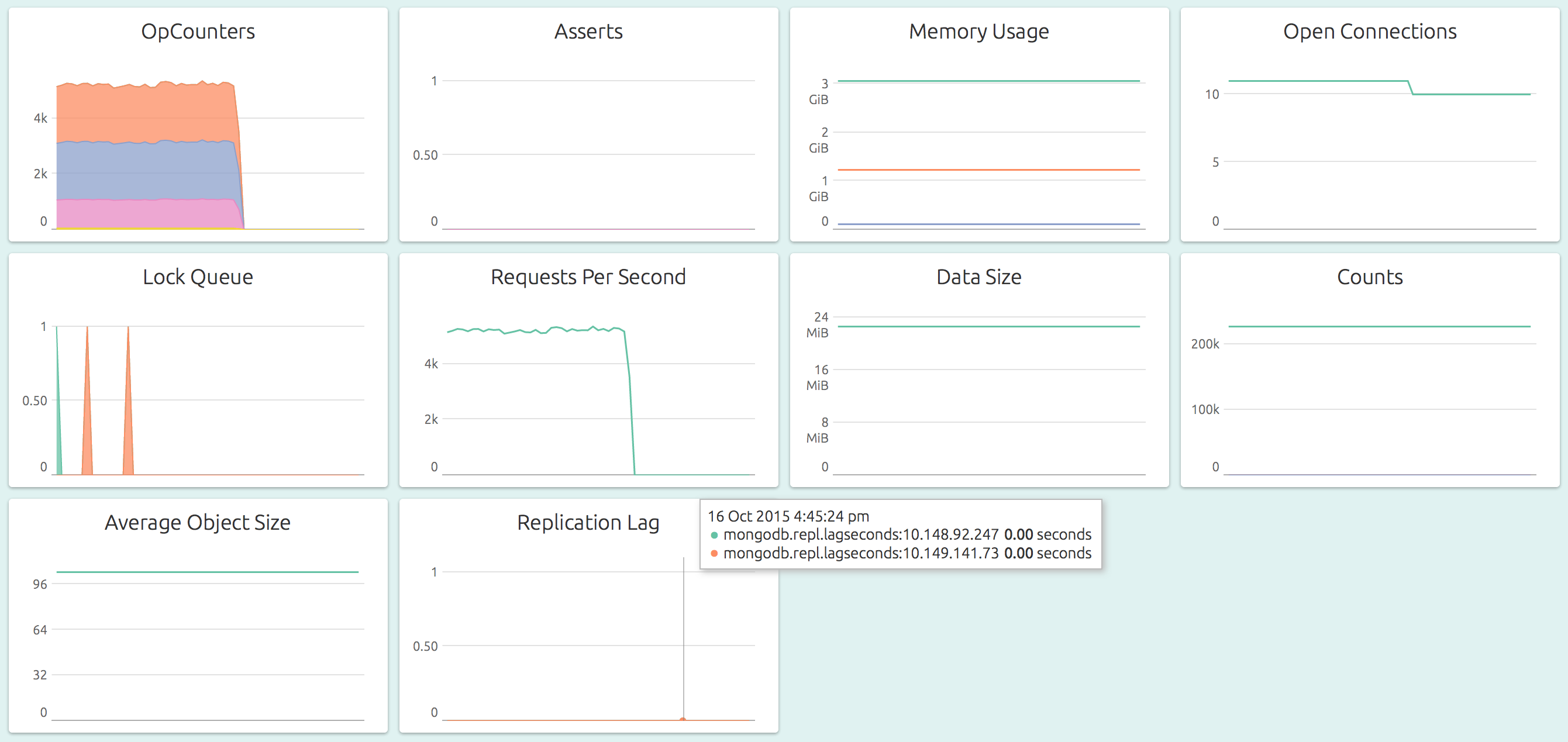
You can go from 0 to this in just a minute or two!
OpsDash dashboards are carefully designed to surface important metrics by default. Here are the graphs that are included in the dashboard:
- OpCounters: The number of operations that MongoDB performs per second, broken up by the type of the operation, is shown in this graph. These counts include all received operations, including ones that were not successful also. The count is per operation, in that even if the operation involves multiple documents, it is counted only once. Secondaries also contribute to the operations count. The MongoDB docs have more info.
- Asserts: This graph plots the number of asserts that are raised each second. While some asserts are benign (for example, a wrong password while invoking a mongo shell), most are not. Persistently high values and deviations from trends should be investigated. The asserts in this graph are broken up by the type of the assert. See MongoDB docs for more info.
- Memory Usage: Shows the resident, virtual and mapped memory sizes used by the MongoDB server process. The value of resident typically gets close to the physical memory size, and mapped to the total database size.
- Open Connections: This graph shows the number of currently open connections to the database. Be sure to set an alert for a reasonable upper limit, considering any connections that might happen for transient jobs, like nightly batch jobs.
- Lock Queue: MongoDB queues readers and writers that need to place temporary locks on the database (see here for more info). This graph plots the number of readers and writers in the queue. Typically, these numbers should be small and should never build up.
- Requests Per Second: The number of requests being served by the database each second.
- Data Size: This graph plots the total size of all databases on the server. OpsDash queries each database on the MongoDB server and aggregates individual sizes to get this value. This number is the size of the actual data (plus any padding), and does not include storage, journal or namespace size.
- Counts: The number of databases, the number of collections (across all databases) and the number of objects (across all collections) are shown in this graph. Counts naturally tend to go up, and are useful in capacity planning.
- Average Object Size: This is a good number to keep an eye on, mainly because of it’s impact on performance. Most processing times will depend on the size of the data it has to pull and push from the database, and the average object size (which is the data size divided by the number of objects; across all databases) is an indicator of this.
If your setup requires that you monitor some additional metrics, that’s easy too. You can add and delete metrics and customize your MongoDB monitoring setup to meet any unique monitoring needs you may have.
MongoDB Replication Monitoring
Production MongoDBs are usually set up with multiple secondaries, which remain in constant sync with the primary. Secondaries may fail to do this for various reasons, like bad network, a crashed mongod process or a primary that is simply too fast for the secondary. These situations result in a “replication lag”.
During normal operations, the replication lag should be within a reasonable upper bound of time, depending on the size and scale of your MongoDB usage.
To monitor replication lag with OpsDash, simply see the “Replication Lag” graph of the primary MongoDB’s dashboard:
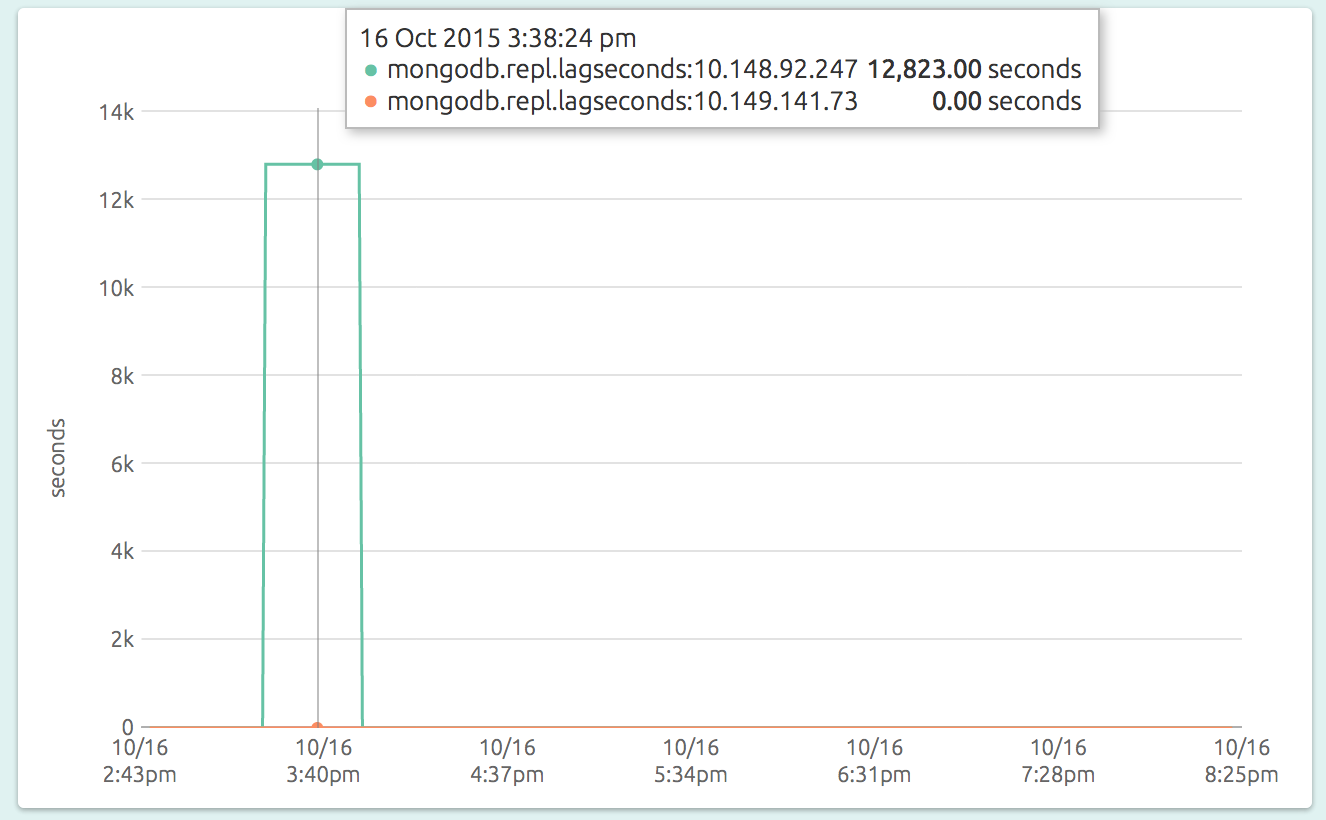
The graph has a line for each secondary, plotting the current replication lag between that and the primary, in seconds. Here you see that one of the secondaries (at 10.148.92.247) lagged for a while before the situation was corrected, while the other secondary (at 10.149.141.73) remained in sync all along.
You’ll want to set warning and critical upper limits for these metrics so that you can catch a runaway secondary before it is too late. You can quickly setup your alerts in OpsDash and send notifications by Slack, Hipchat, OpsGenie, PagerDuty or Email.
Learn More:
- Blog Post: How to setup a secure MongoDB 3.4 server on Ubuntu 16.04
- Blog Post: MongoDB Monitoring with OpsDash
New here?
OpsDash is a comprehensive solution for server monitoring, service monitoring, database monitoring and application metrics monitoring. You can use OpsDash for monitoring MySQL, PostgreSQL, MongoDB, memcache, Redis, Apache, Nginx, Elasticsearch and more. It provides intelligent, customizable dashboards and spam-free alerting via email, HipChat, Slack, PagerDuty, OpsGenie, VictorOps and Webhooks. Send in your custom metrics with StatsD and Graphite interfaces built into each agent.