The first beta release of PostgreSQL 10 was announced a couple of days ago. This release brings with it the much-awaited logical replication feature.
We decided to take it for a spin and see how it works.
Streaming Replication
The existing replication feature built into PostgreSQL is called Streaming Replication. If you aren’t familiar with it, check out our popular blog post about it.
Essentially, you can use streaming replication to maintain multiple, up-to-date, read-only replicas of a single PostgreSQL server (technically, a single PostgreSQL cluster). This contains databases, roles (users), tablespaces and more.
With streaming replication, you get all or nothing. The replicas (standbys) are byte-for-byte copies of the main server’s set of on-disk files. Streaming replication is perfect for maintaining a hot standby server, to which you can failover in case the primary server fails. They are also good for maintaining read-only replicas for analytics-related use cases.
What streaming replication cannot do is to replicate a subset of the data in the main server. If you want to have an off-server copy of, say a single table, it won’t be possible with streaming replication.
You also can’t modify the data in the replica with streaming replication. Let’s say you use the replica for analytics, and need to delete the data once your daily batch jobs are done processing it. The deletion won’t work because the replica is strictly read-only with streaming replication.
Streaming replication also does not work across PostgreSQL versions. You can’t upgrade PostgreSQL versions without downtime by trying to bring up a standby with the next PostgreSQL version then failing over to it.
Typically, you’d use one of the tools listed here to implement such requirements. But now with logical replication, it’s possible to do most of these without external tools. At the very least, it is a powerful tool on which to further build customized solutions.
Logical Replication
Logical Replication can replay, logically, the changes (as in insert, update, delete of rows) happening to one or more persistent tables in a database.
The source server must create a named object called a Publication. A publication serves as an endpoint from which a log of changes can be fetched by a Subscription. The subscription is created on another, a destination, server. The subscription includes a standard connection string that tells how to connect to the source server.
Let’s see how it works. First, we have a server that has a database dbsrc,
which has a table t1:
dbsrc=# create table t1 (id integer primary key, val text);
CREATE TABLE
dbsrc=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
val | text | | |
Indexes:
"t1_pkey" PRIMARY KEY, btree (id)
dbsrc=#We’ll also need a user with replication privileges:
dbsrc=# create user replicant with replication;
CREATE ROLE
dbsrc=# grant select on t1 to replicant;
GRANT
dbsrc=#Unlike streaming replication, the replication user needs read access to the tables themselves.
Let’s insert some rows into t1 before we start replication:
dbsrc=# insert into t1 (id, val) values (10, 'ten'), (20, 'twenty'), (30, 'thirty');
INSERT 0 3
dbsrc=# select * from t1;
id | val
----+--------
10 | ten
20 | twenty
30 | thirty
(3 rows)
dbsrc=#OK, here comes the first logical replication related command. We’ll create a
publication pub1 that will serve as an endpoint for replicating changes
happening to the table t1:
dbsrc=# create publication pub1 for table t1;
CREATE PUBLICATION
dbsrc=#Now let’s connect to another server, with another database called dbdst.
Unlike streaming replication, we need to create the table t1 here first. If we
try to create a subscription without that:
dbdst=# create subscription sub1 connection 'dbname=dbsrc user=replicant' publication pub1;
ERROR: relation "public.t1" does not exist
dbdst=#it doesn’t work. So let’s create the table:
dbdst=# create table t1 (id integer primary key, val text, val2 text);
CREATE TABLE
dbdst=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
val | text | | |
val2 | text | | |
Indexes:
"t1_pkey" PRIMARY KEY, btree (id)
dbdst=#Ha! We snuck another column in there. Let’s create the subscription and see what happens:
dbdst=# create subscription sub1 connection 'dbname=dbsrc user=replicant' publication pub1;
NOTICE: synchronized table states
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTION
dbdst=# select * from t1;
id | val | val2
----+--------+------
10 | ten |
20 | twenty |
30 | thirty |
(3 rows)
dbdst=#It’s replicated! We can see the initial set of rows in the destination table. Further changes get replicated as well:
dbsrc=# delete from t1 where id=10;
DELETE 1
dbsrc=# insert into t1 (id, val) values (40, 'forty');
INSERT 0 1
dbsrc=#Here they are on the destination:
dbdst=# select * from t1;
id | val | val2
----+--------+------
20 | twenty |
30 | thirty |
40 | forty |
(3 rows)
dbdst=#Things work as expected. Let’s try some modifications on the destination and see what happens:
dbdst=# update t1 set val2 = 'foo';
UPDATE 3
dbdst=# delete from t1 where id = 20;
DELETE 1
dbdst=# select * from t1;
id | val | val2
----+--------+------
30 | thirty | foo
40 | forty | foo
(2 rows)
dbdst=#Let’s also do some modifications on the source:
dbsrc=# insert into t1 (id, val) values (50, 'fifty');
INSERT 0 1
dbsrc=# update t1 set val = 'bar' where id = 30;
UPDATE 1
dbsrc=# select * from t1;
id | val
----+--------
20 | twenty
40 | forty
50 | fifty
30 | bar
(4 rows)
dbsrc=#And here’s what we get at the end of it all:
dbdst=# select * from t1;
id | val | val2
----+-------+------
40 | forty | foo
50 | fifty |
30 | bar |
(3 rows)
dbdst=#Interesting! We see that:
- the row we deleted at the destination stays deleted
- the row we updated only at the destination stays the same
- the row we updated first at the destination and then at the source got updated entirely – the entire tuple has been replaced, and our changes to “val2” column have been lost
- the row we inserted at the source was replicated
Let’s try something else now. What happens if we delete the table t1 at the
destination and then recreate it?
dbdst=# drop table t1;
DROP TABLE
dbdst=# create table t1 (id integer primary key, val text, val2 text);
CREATE TABLE
dbdst=# select * from t1;
id | val | val2
----+-----+------
(0 rows)
dbdst=#Oops, we broke the magic! To get the sync back on, we need to refresh the subscription:
dbdst=# alter subscription sub1 refresh publication;
NOTICE: added subscription for table public.t1
ALTER SUBSCRIPTION
dbdst=# select * from t1;
id | val | val2
----+--------+------
20 | twenty |
40 | forty |
50 | fifty |
30 | bar |
(4 rows)
dbdst=#Ah, we’re back in business! Refreshing is needed in other cases too, like if the publication was altered to include another table.
Going From Here
There are a few more things that logical replication can do that we didn’t cover here:
- publishing only insertions, updates or deletions to tables
- pulling in changes from multiple sources into one destination
- adding more tables into an existing publication
- transactional consistency – destinations see only complete and committed transactions
- streaming replication – streaming and logical replication features work independently without interfering with each other
If you’re planning to get your hands dirty trying out logical replication for yourself, here are somethings that’ll help:
- In the source server’s
postgresql.conf, setwal_level = logical,max_replication_slots = 10. - Also ensure
pg_hba.confis updated for the replication user to connect. - In the destinaton server’s
postgresql.conf, setmax_replication_slots = 10,max_logical_replication_workers = 4andmax_sync_workers_per_subscription = 2. - We had to compile the binaries from the source tarball available here.
And here are links to relevant documentation:
Let us know how it goes!
Monitoring PostgreSQL With OpsDash
With our own product, OpsDash, you can quickly start monitoring your PostgreSQL servers, and get instant insight into key performance and health metrics including replication stats.
Here’s a default, pre-configured dashboard for PostgreSQL.
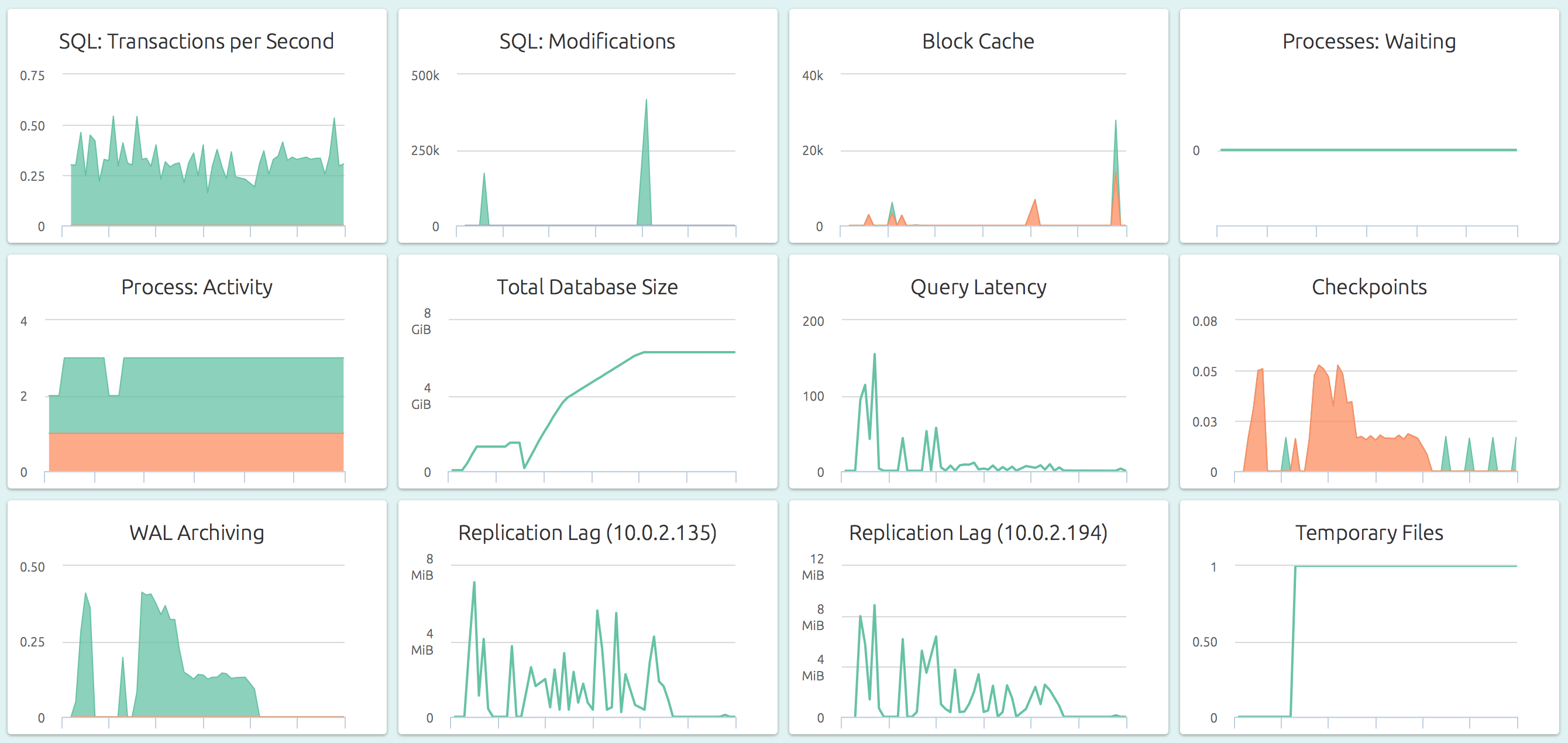
OpsDash strives to save you the tedious work of setting up a useful dashboard. The metrics you see here were carefully chosen to represent the most relevant health and performance indicators for a typical PostgreSQL instance.
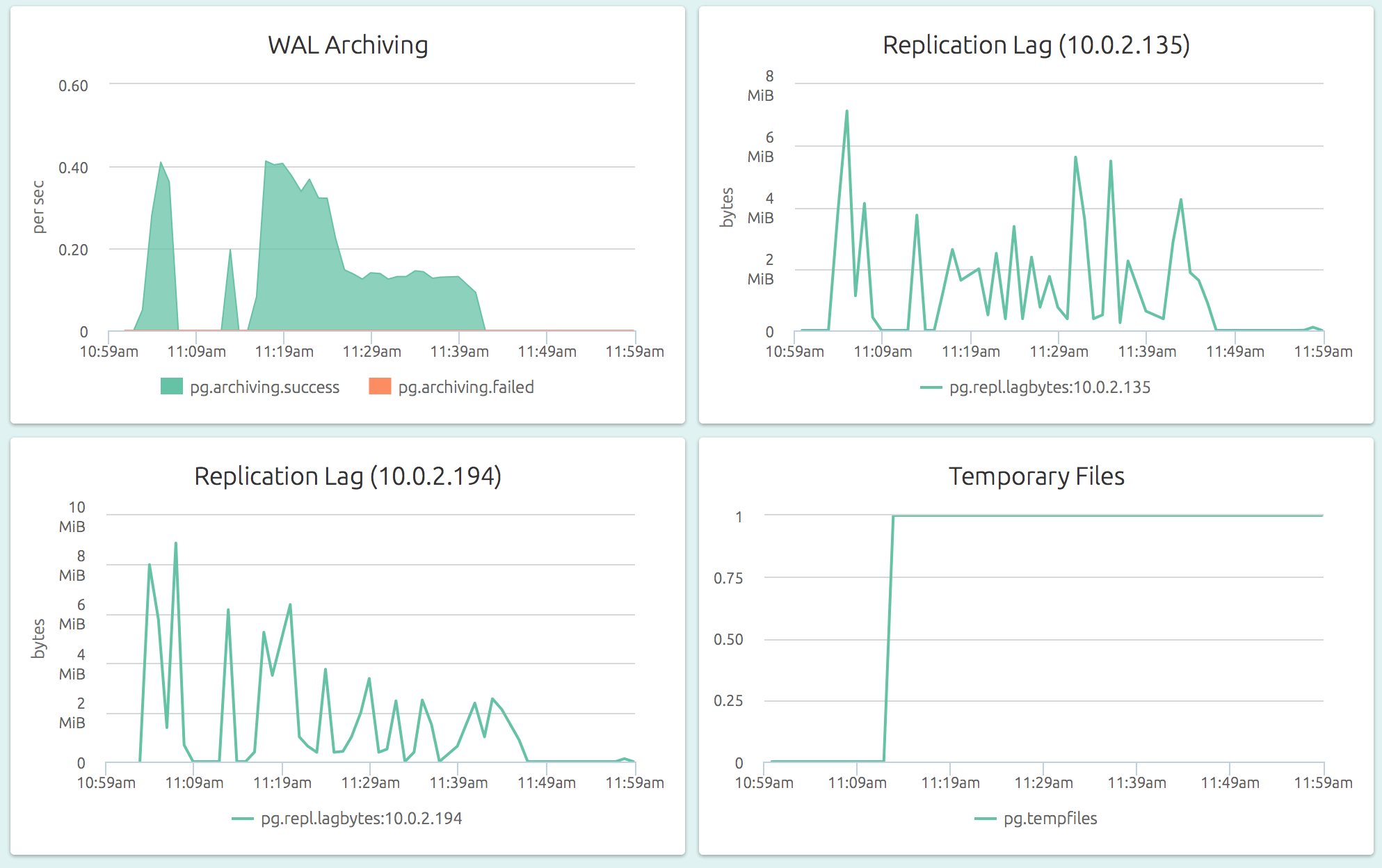
OpsDash understands the streaming replication feature of PostgreSQL and displays per-slave replication status on the master:
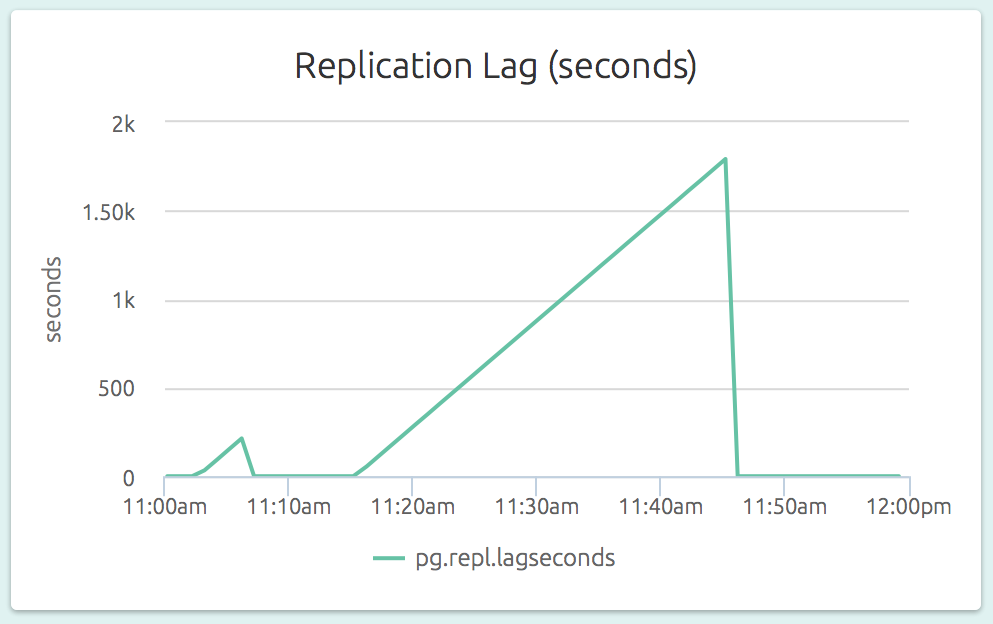
The replication lag (as a length of time) is also visible on a slave’s dashboard. In the graph below (part of the dashboard of a slave), we can see that the slave could not catch up to the master’s changes for a while.
Sign up for a free 14-day trial of OpsDash SaaS today!